
Metadata-driven architecture for Data Lakehouse
How we used metadata-driven architecture to build out and automate Data Lakehouse
Overview
One of our client companies streams a high volume of real-time business-critical events using the Kafka ecosystem. For security reasons, the company is using a “collector application” that uses a JSON Schema document such that it is only possible to publish events to topics that are whitelisted in that document.
Currently the business partners are not getting access to the data soon enough to make decisions due to the high latency (from hours up to days) as the data is batch-processed using Amazon S3 and Apache Spark on Amazon EMR cluster. Additionally, the inability of the current system to handle traffic at this scale results in significant data loss, in some cases as high as 15%. From a security perspective, all the topics are available to all partners right now, whereas they should only be accessible to the partners who actually own the topic. Finally, the solution is not very adaptable to changes right now. Introducing new topics/events to the system is a manual process, which is time-costly and prone to error.
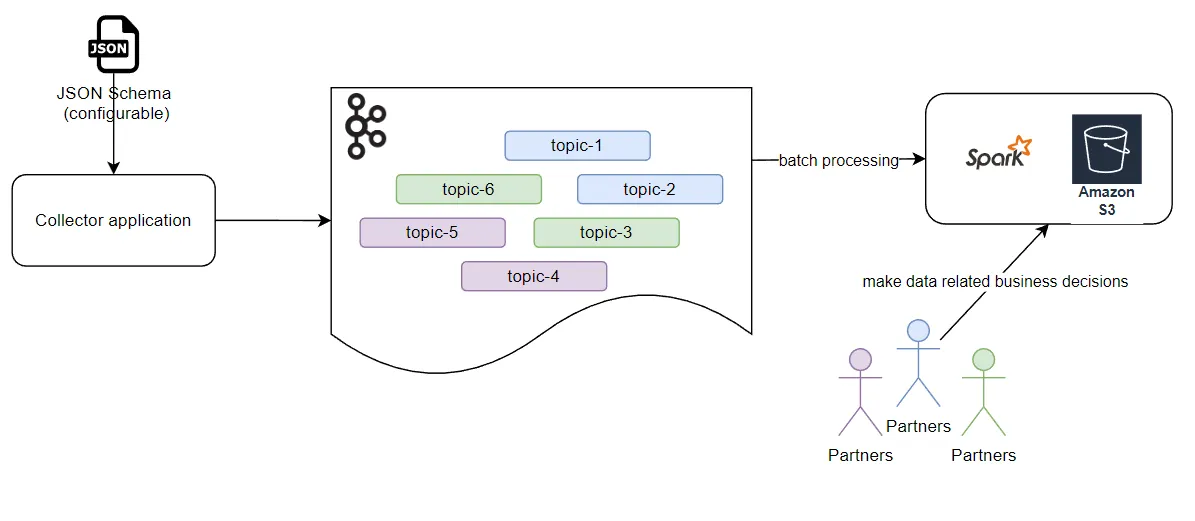
Thus we proposed and proved at scale a new metadata-driven architecture with the objectives to improve the latency, scalability, cost, security, data integrity and adaptability of the system.
The intended audience of the article is Data Engineers, Data Architects and Solution Architects.
Approach
The proposed solution is to build out and automate a Data Lakehouse using metadata-driven architecture without changing the existing JSON Schema document. This solution consists of multiple concepts that will be explained next.
A Data Lake is a data storage repository that can store large amount of structured and semi-structured data. The Data Lake usually contains many layers and is implemented using the native storage of a cloud provider. For example, Amazon S3 can be used to build a data lake using AWS cloud.
The Data Lake ingests the data from multiple sources and stores the data unmodified in ingestion layer (also called as raw layer or bronze layer). The Data Lake has some intermediate layers to perform data transformations. The further the data is moved in terms of layers, the closer the data is getting to its eventual use case, whether it’s building a BI report, an ML model or the predictions of that ML model. There is no hard limit to the number of layers in that architecture.
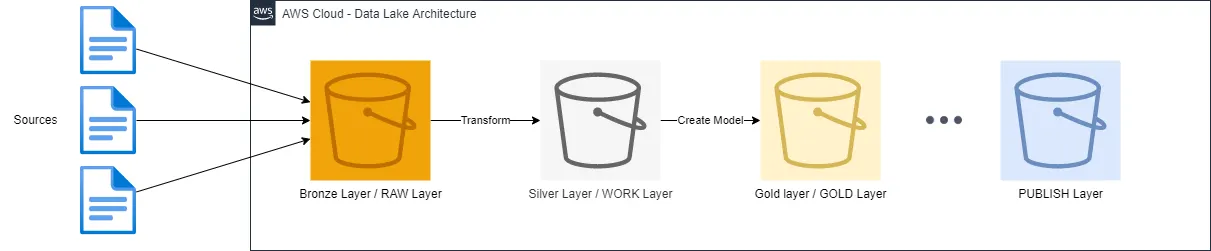
A Data Lakehouse combines the Data Lake with the Data Warehouse into a single cohesive data platform. Due to its unique set of features, Snowflake is one of the leading Lakehouse platform. Given an AWS as the cloud platform, Snowflake can leverage Amazon S3 as a storage resource. It is possible to create a Storage Integrations in Snowflake and reference to it as a Stage. Thus all the permanent objects are eventually stored in Snowflake managed S3 buckets. The data lake layers can be created in Snowflake as separated databases
Solution
As a solution, we created a code generation engine that takes the existing JSON Schema as input, generates the DDL and executes the statements by the engine producing an infrastructure for all the defined entities in the configuration document. The solution has 2 sources — an AWS MSK and a JSON Schema.
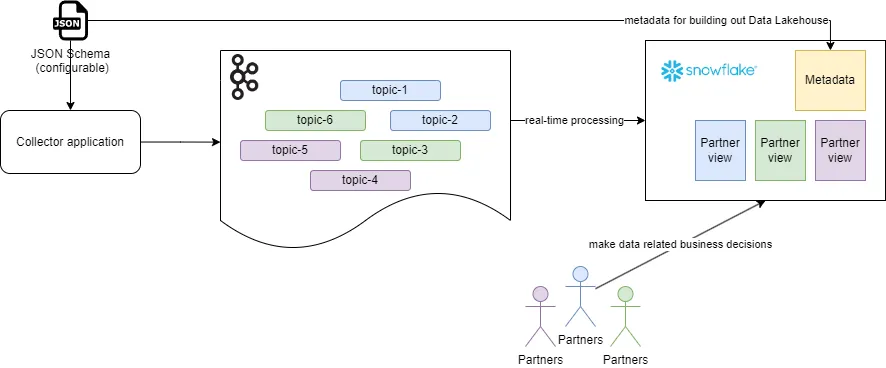
The AWS MSK is a Kafka cluster where all of the company’s real-time event-streaming is done. The JSON Schema is the company’s existing object that whitelists all the allowed topics in the Kafka Cluster together with additional attributes, defining ~300 topics. In addition to the name of the topic, each configuration specifies the owner of that topic and set of roles who can see all the fields in the event in an unmasked manner. As this is metadata/configuration driven architecture, the JSON Schema defines what is happening in other parts of the system.
The Configuration table stores currently active versions for all of the topics. As per the JSON Schema, there are going to be 300 active configurations/rows in that table. The system is using Snowflake streams to capture the change in configuration tables. When changes are encountered, a Snowflake task is executed to build out all Snowflake components for that specific topic.
The Raw message table serves as the raw layer of the Data Lakehouse consisting of a VARIANT column supporting semi-structured data and is the landing zone for the events coming from Kafka cluster for one specific topic. The system creates a Dynamic Data Masking policy from the JSON Schema, and applies it to the raw message table. From security perspective, this means that this table as well as the objects derived from that table have specific fields masked (e.g. PII fields). Only dedicated roles specified in the JSON Schema can see unmasked data.
The system uses a Kafka Connect Cluster to ingest the data from a topic to the raw message table. We created a containerized Kafka Connect instance that is using the Snowflake Kafka Connector implementation for loading the data. The Kafka Connect Cluster forms out of many instances and can thus be horizontally scaled in an automatic manner based on the load. The running cluster exposes a REST API that can be used to configure the Kafka Snowflake Connector inside the cluster.
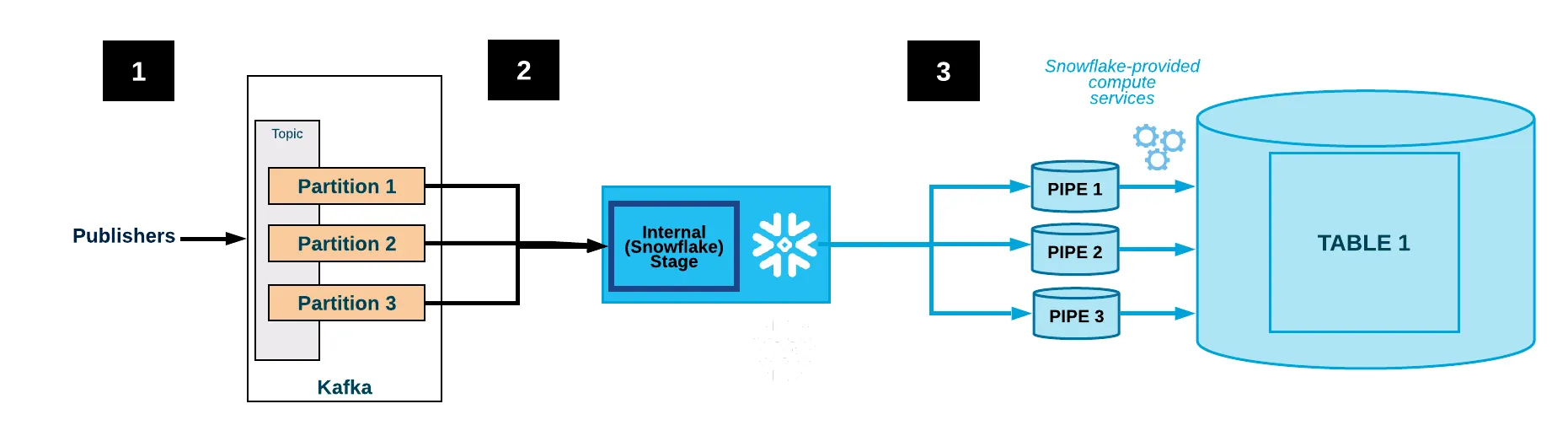
As this architecture must be metadata driven, the system must be able to respond to the changes in the metadata. We created a Utility Service to perform this function. For example, when new topic is added to the JSON Schema, the Utility Service updates Kafka Connect Cluster via the REST API to also loads the data from the newly added topic into Snowflake.
Results
To be successful, the system had to have an average latency between the Kafka event and the Snowflake table of no greater than 5 minutes, so that critical business decisions could be made in a timely manner. We managed to over-deliver on this goal by implementing a near real-time solution using micro-batching instead of earlier batch-processing.
The combination of Kafka Connect Cluster’s horizontal scalability and Snowflake’s serverless Snowpipe feature enabled us to benchmark the system during performance tests on 41 topics with ~4 million events per minute reaching Kafka. Cost estimations under both heavy and normal loads show a significant reduction compared to the previous solution. That way we configured the solution to handle the peak load and be scalable. Given the performance and cost estimations we managed to predict the yearly cost of that solution for the company.
One of the biggest game changer is the new security policy we introduced. Using the Dynamic Masking Policy, the sensitive data is now masked by default in the first layer in data lake, and all subsequent layers. Additionally, the data was only accessible to the owner of the specific topics. Being masked, it is not even accessible to Administrators.
Compared to the previous solution, which suffered from a data loss of up to 15%, during the performance test of the new system with a total load of ~230 million events, no data loss was detected.
Finally, the solution is now metadata-driven such that implementing a change in the metadata causes the system to adapt to the change without any manual intervention.
Conclusion
The metadata-driven architecture to build out and automate Data Lakehouse turned out to be an excellent and performant solution to adapt the changes and fulfill the Company’s requirements in terms of latency, scalability, cost, security, data loss and adaptability of the system.
We believe that implementing similar metadata-driven architecture in systems where new events are likely to be introduced in the future is less error-prone, decreases the development effort and guarantees fast availability of data in the Data Lake.
